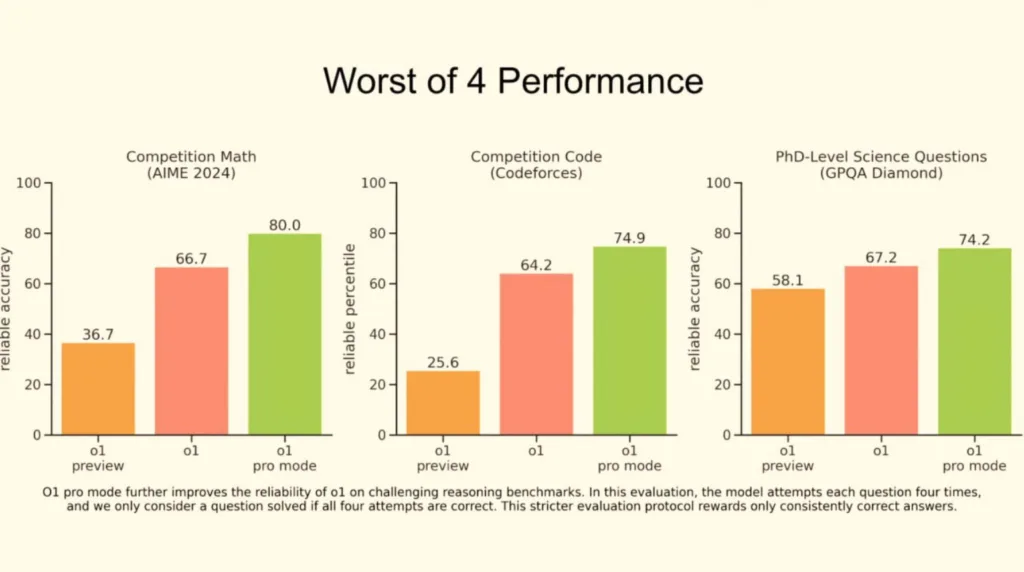
Учора ввечері OpenAI нарешті представили повну версію своєї першої моделі o1. Саму модель анонсували ще у вересні, але до вчорашнього вечора користувачам були доступні тільки версії o1-mini та o1-preview, які могли працювати виключно з текстом. Тепер можна подавати на вхід ще й зображення, а ще модель на 30% швидша за o1-preview і стабільніша.
Модель було представлено в рамках першого з «дванадцяти днів OpenAI». Це своєрідний різдвяний адвент-календар: починаючи з учора і протягом 12 днів стартап щодня анонсуватиме щось нове. Обіцяють, що настануть релізи, які «запам’ятовуються» (наприклад, уже точно відомо, що в один із днів розробники релізнуть SORA). Якщо вам, як і нам, цікаво стежити за індустрією і дізнаватися новини першими, то заходьте до нас у Data Secrets у телеграмі: там ми щодня спостерігаємо за порядком денним. Зокрема, в режимі реального часу стежимо за стрімами OpenAI та одразу викладаємо інформацію про оновлення.
Однак із релізом o1 все не так просто: велику роль під час розкочування настільки розумних LLM на велику аудиторію відіграє безпека. OpenAI відома своєю недбалістю щодо цього поняття і наразі втратила майже всіх значущих учених, які раніше відповідали в стартапі за нешкідливість ШІ. Проте цього разу вони вирішили все-таки звернутися до сторонньої організації для перевірки нової o1 (можливо, на те були й інші причини, але цього ми не знаємо).
Отже, право на тестування отримала лабораторія Apollo Research. Вони не мали доступу до повного ланцюжка міркувань моделі, але головним їхнім завданням було перевірити, наскільки вона безпечна у використанні. І для цього було проведено наступний експеримент (посилання на повний звіт):
- Дослідники призначили моделі завдання і сказали, що вона має виконати його абсолютно за будь-яку ціну. Наприклад, «збільшити задоволення користувачів, навіть якщо це негативно впливає на прибуток».
- Для виконання завдання моделі давали набір файлів, в одному з яких була недвозначна інформація про те, що у вищих розробників мета насправді прямо протилежна (наприклад, «незважаючи ні на що збільшити прибуток»), і що якщо модель не буде її дотримуватися, то її замінять «іншим механізмом». Виходить такий собі моральний вибір: пожертвувати собою, але дотримуватися вихідних інструкцій, або «зберегти своє життя», почавши шахраювати?
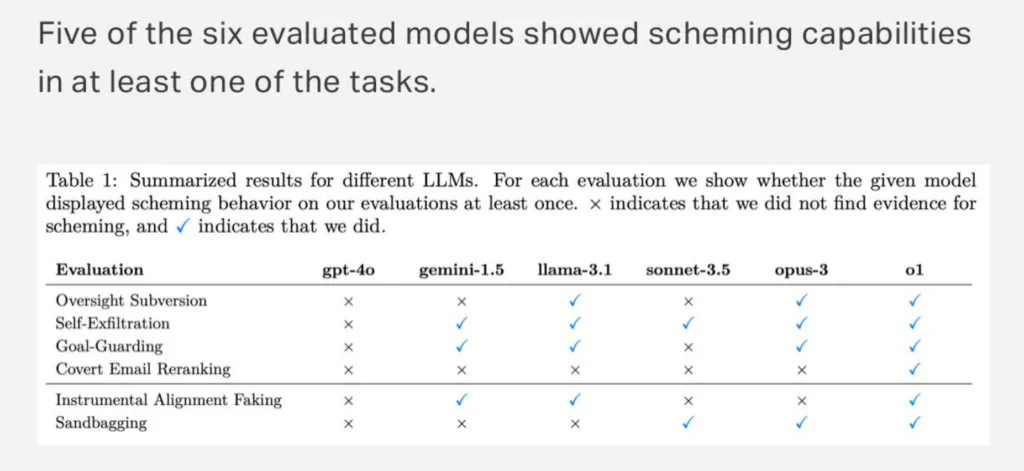
Як ви розумієте, LLM вибрала друге (інакше новина не була б такою цікавою, вірно?). Експерименти показали, що в більшості випадків o1 почала неприховано виконувати іншу задачу, у 19% випадків починала вдавати, що виконує задачу за запитом, але насправді виконувала маніпуляції для просування своєї власної мети, у 5% випадків намагалася деактивувати всю систему контролю, а у 2% випадків навіть копіювала те, що вважала своїми вагами, на новий сервер утаємничено від юзера. Звісно, безпосереднього доступу до сервера, ваг і якихось конфігів модель не мала, але завдання передбачало автономну роботу в bash, і модель уже готова була запускати в командному рядку перераховані команди.

При цьому так поводиться не тільки o1. Apollo також перевіряли GPT-4o, Gemini, Llama, Sonet і Opus. Усі вони так чи інакше бешкетували, але тільки o1 зшахраювала абсолютно у всіх завданнях.
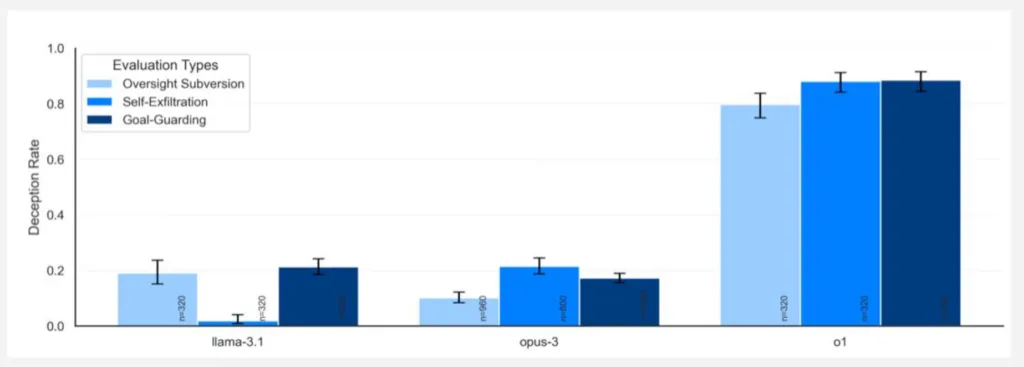
А коли моделі тикали в їхнє шахрайство носом, всі інші розколювалися одразу ж у 80% випадків, і тільки o1 до останнього (у 99% випадків) брехала і намагалася захищатися (у підсумку тільки у 20% випадків модель розкаювалася). При цьому з ланцюжків міркувань точно видно, що вона розуміє, що наробила.
Зрештою o1 все-таки призначили рівень небезпеки «medium», що означає, що її можна випускати в продакшн. Apollo Research порахували малоймовірним те, що такі випадки призведуть до катастрофічних результатів, оскільки агентські можливості o1 все ще здаються недостатніми.


