Педагоги в процесі навчання дітей поглиблюють і власні знання. Це пов’язано з тим, що викладання змушує людину чітко структурувати інформацію та виявляти прогалини. Виявилося, цей принцип працює і з великими мовними моделями (LLM).
Китайські вчені з Університету Цінхуа адаптували методику навчання через викладання (Learning by Teaching, LBT) для тренування нейромереж. Під час досліду потужна модель GPT-4 передавала знання простішій GPT-3.5.
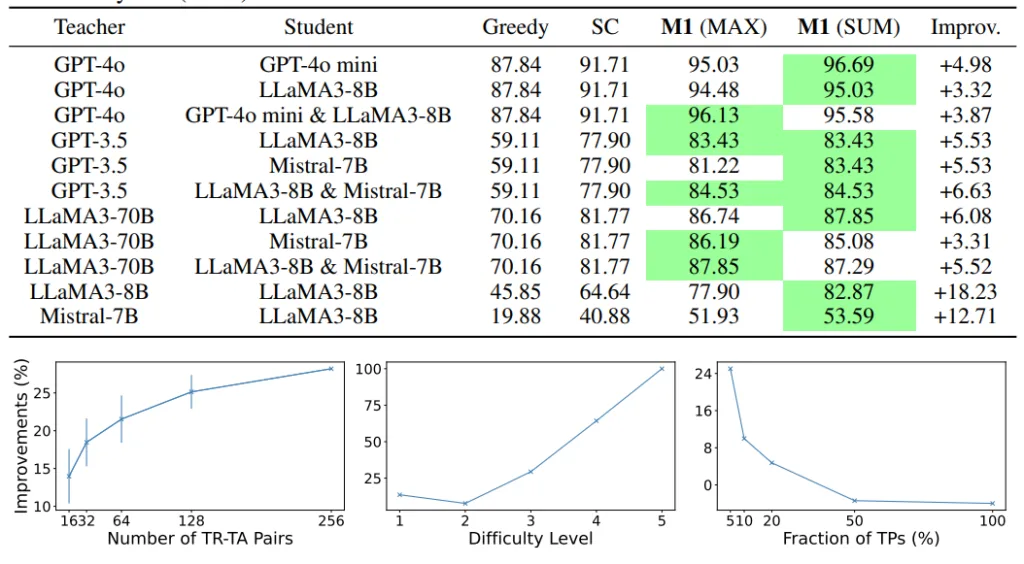
Як це працює
➡️ Сильний тренує слабкого. У процесі навчання «вчитель» відповідає на запитання «учня» і пояснює йому складні концепції, які молодша модель ще не може зрозуміти.
➡️ Узагальнення знань. Сильна модель змушена формулювати відповіді так, щоб їх розуміла слабка модель. Таке «узагальнення» змушує «вчителя» по-новому поглянути на свої знання, спрощуючи та перебудовуючи їх.
➡️ Покращення сильної моделі. Під час тренування «вчитель» аналізує власні знання. Це допомагає сильній моделі виявити й усунути свої слабкі сторони або навіть знайти нові способи розв’язання задач. У підсумку вона вдосконалює алгоритми, підвищує точність прогнозів і покращує загальну якість роботи.
Навіщо це потрібно
LBT відкриває нові перспективи для розвитку штучного інтелекту. В OpenAI вже використовують нову потужну модель Strawberry для навчання нейромережі Orion, яка прийде на зміну GPT-4o. І, судячи з інсайдерської інформації, тренування проходить успішно. До того ж, один «учитель» може натаскувати одразу кілька «учнів». А використання такого підходу для поліпшення LLM допомагає знизити залежність від даних, створених людиною.


