У найближчі 2 роки може виникнути найдивніший дефіцит за всю історію людства – закінчаться тексти, створені людьми. Це призведе до того, що мовні моделі (LLM) вичерпають дані для навчання, спричинивши кризу масштабування. Такого висновку дійшли дослідники, які вивчають вплив AI на наш світ.
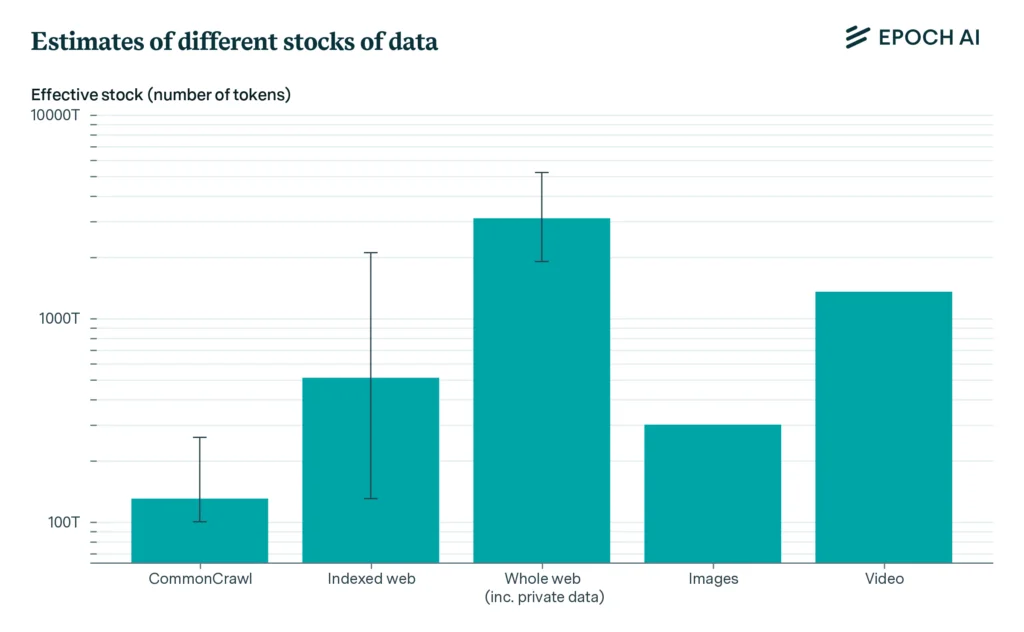
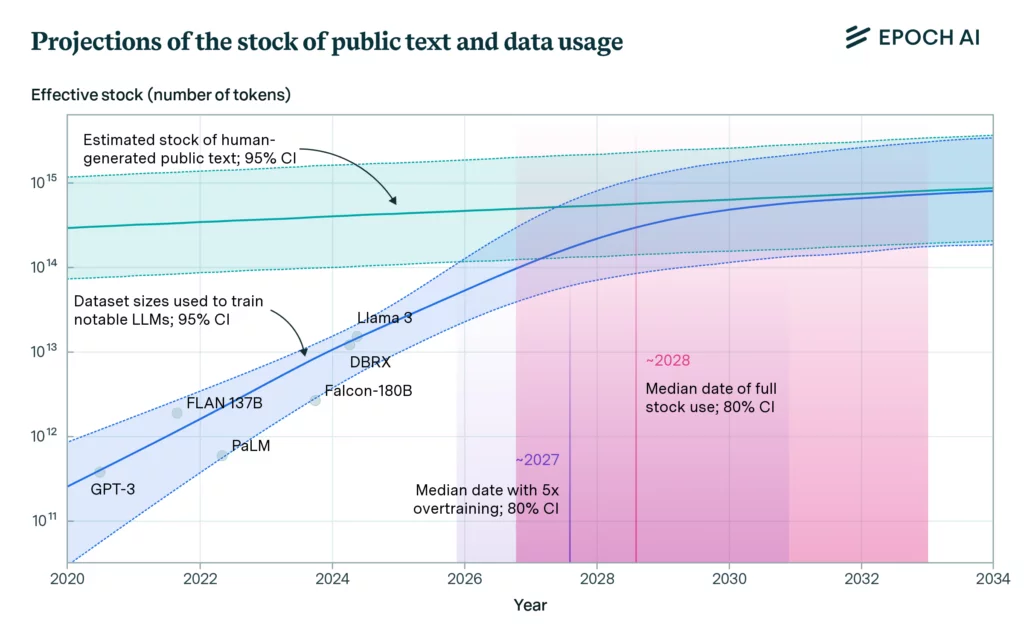
300 трильйонів токенів – стільки створеного людством тексту на сьогодні доступно для навчання AI-моделей.
0️⃣ “Посуха” без даних
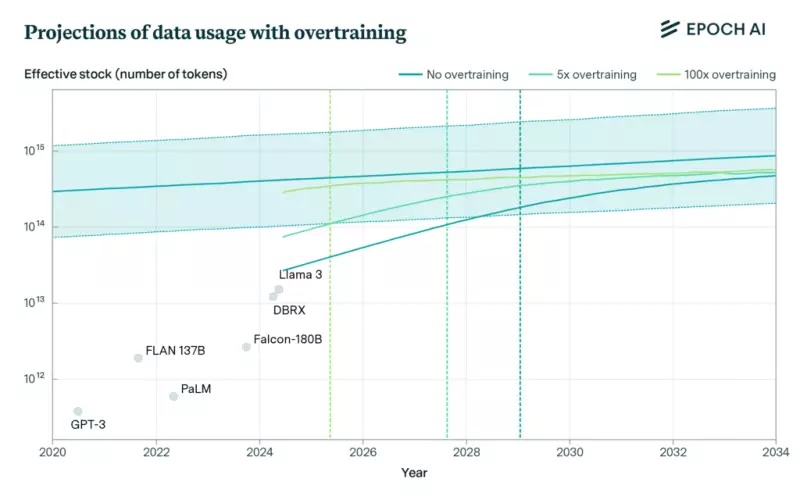
2026-2032 рр. – цей період дослідники вважають найімовірнішим терміном для повного вичерпання текстових даних для навчання LLM. Він може настати та раніше, якщо моделі будуть сильно перенавчені в умовах AI-перегонів і масштабування популярних LLM.
Три головні висновки дослідників
1️⃣ Саме текстові дані стануть вузьким місцем у розвитку більш просунутих LLM.
2️⃣ Синтетичні дані від AI ще недостатньо вивчені. Вони корисні у вузьких галузях, як-от математика і програмування. Є думка, що такі дані можуть бути небезпечні, оскільки AI може робити помилки під час їх створення.
3️⃣ Закриті дані, такі як особисті повідомлення, навряд чи будуть використовуватися у великих масштабах через юридичні проблеми.
🔠 Вихід із кризи
Дослідники пропонують кілька рішень для розвитку LLM:
➡️Синтетические дані.
➡️Обучение на інших видах даних.
➡️Повышение ефективності даних.
💲 Кому я можу продати свої дані
Компанії вже пропонують інтернет-користувачам грошову винагороду за їхні персональні дані, які можна використовувати для навчання AI-моделей. Ось деякі з них:
➡️ TIKI – за доступ до мобільних пристроїв користувачів. Їх цікавить поведінка людей у додатках, які уклали партнерство з TIKI.
➡️ Caden – за доступ до особистих кабінетів у Netflix і Amazon. Йдеться про заробіток від $5 до $50 на місяць.
➡️ Invisible – пропонує доступ до платних новинних статей в обмін на демографічні та поведінкові дані, включно з інформацією про щеплення та політичну приналежність користувачів. Компанія планує обмінювати ці дані на цифрові підписки вартістю від $4 до $15 на місяць.