Sesame AI, каліфорнійський стартап, використовує нетрадиційний підхід до голосового ШІ, навмисно додаючи дефекти у свою мову. Їхня нова модель являє собою перший крок до більш автентичних діалогів і того, що вони називають «присутністю голосу» в системах ШІ.
Згідно з результатами попереднього тестування, найбільш вражаючими особливостями Sesame є такі тонкі елементи, як мікропаузи, акценти та сміх під час розмови. В одному з діалогів аватар Sesame Майя в режимі реального часу відреагувала на раптовий сміх користувача, продемонструвавши емоційну обізнаність.
Система навмисно імітує людську поведінку, наприклад, виправляє себе в середині речення і перепрошує за перерви в мовленні. Techradar особливо відзначив ці навмисні недосконалості, підкресливши, що вони відрізняються від відполірованого корпоративного стилю ChatGPT або Gemini.
У змодельованих сценаріях, як-от обговорення стресу на роботі або планування вечірки, система пропонувала контекстуально відповідні відповіді та запитання, а не використовувала шаблонні фрази.
Система обробляє мову, використовуючи семантичні маркери для лінгвістичних властивостей і фонетики, а також акустичні маркери для таких характеристик звуку, як висота тону й наголос. Для оптимізації навчання аудіодекодер навчається тільки на одній шістнадцятій частині аудіокадрів, тоді як семантична обробка використовує весь набір даних.
Модель навчалася на одному мільйоні годин аудіоданих англійською мовою за п’ять епох. Вона може обробляти послідовності з 2048 токенів (близько двох хвилин аудіо) у наскрізній архітектурі. Цей підхід відрізняється від традиційних систем перетворення тексту на мову інтегрованим опрацюванням тексту та аудіо.
Під час сліпих тестів із Sesame учасники не могли відрізнити CSM від реальних людей під час коротких діалогів. Однак у довших діалогах все ж виявлялися обмеження, такі як випадкові неприродні паузи та звукові дефекти.
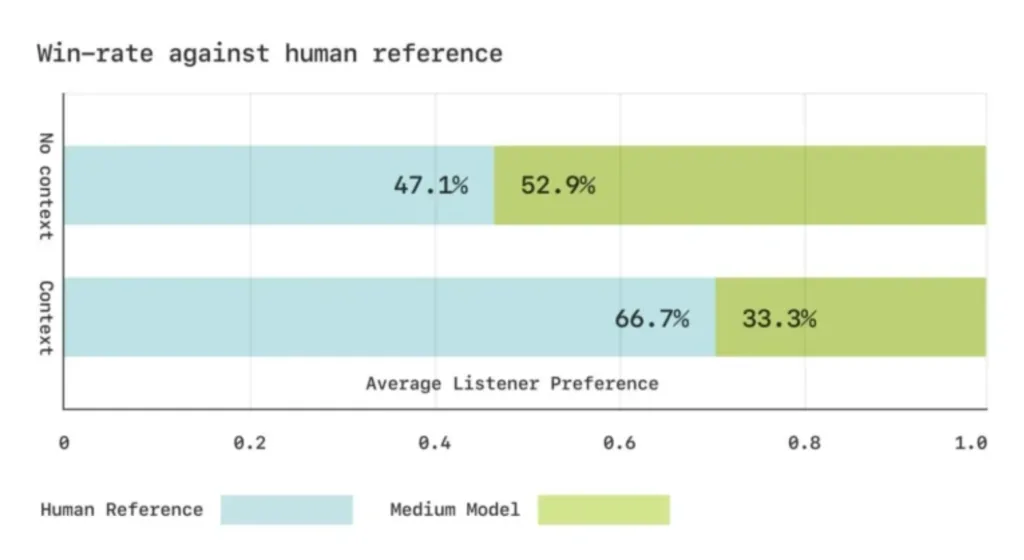
Sesame розробила спеціальні фонетичні тести для оцінки ефективності моделі. У тестах на сприйняття на слух учасники оцінили згенеровану мову як еквівалентну реальним записам, коли вона звучала без контексту, хоча за наявності контексту вони все одно віддавали перевагу оригіналу.
Sesame планує випустити ключові компоненти свого дослідження у відкритому доступі за ліцензією Apache 2.0. Найближчим часом вони мають намір збільшити масштаб моделі та розширити охоплення навчання, включивши в нього понад 20 мов.
Компанія акцентує увагу на інтеграції попередньо навчених мовних моделей і створенні систем із повним дуплексом. Ці системи здатні аналізувати динаміку розмови, включно зі зміною мовців, паузами і швидкістю мовлення, безпосередньо на основі даних. Для досягнення цієї мети знадобляться значні зміни у всіх аспектах обробки, починаючи з роботи з даними і закінчуючи методами подальшої обробки.
«Створити цифрового компаньйона з голосовим супроводом непросто, але ми стабільно просуваємося за кількома напрямками, включно з індивідуальністю, пам’яттю, виразністю і доречністю», – зазначають розробники.
Компанія Sesame AI, заснована колишнім технічним директором Oculus Бренданом Ірібе і його командою, отримала значне фінансування серії A від Andreessen Horowitz. Демо-версія вже доступна.
Джерело


