Дослідники Гонконзького університету науки та технології представили відкриту нейромережу для генерації музики. Автори проєкту називають свою розробку безкоштовним аналогом Suno. Модель може генерувати інструментальні композиції та пісні.

У дослідженні зазначається, що в задачах генерації пісень на основі тексту все ще немає чіткого розуміння, як розв’язувати деякі проблеми. Наприклад, у багатьох реалізаціях не виходить зберегти характер композиції до самого кінця, а ще нейромережа спотворює слова, щоб вони краще лягали на музику. Є вдалі пропрієтарні реалізації, але в дослідників немає можливості дізнатися, які підходи в них застосовуються.
Для розв’язання цієї проблеми дослідники розробили сімейство моделей машинного навчання YuE на базі мовної моделі LLaMA. Нейромережа дає змогу генерувати треки тривалістю до п’яти хвилин з узгодженою музичною структурою. Для цього автори проєкту використовували аудіотокенізатор з поліпшеним розумінням семантики для зниження витрат на навчання і текстовий ланцюжок думок для кращої роботи з контекстом. Для масштабованості застосували триступеневий метод навчання.
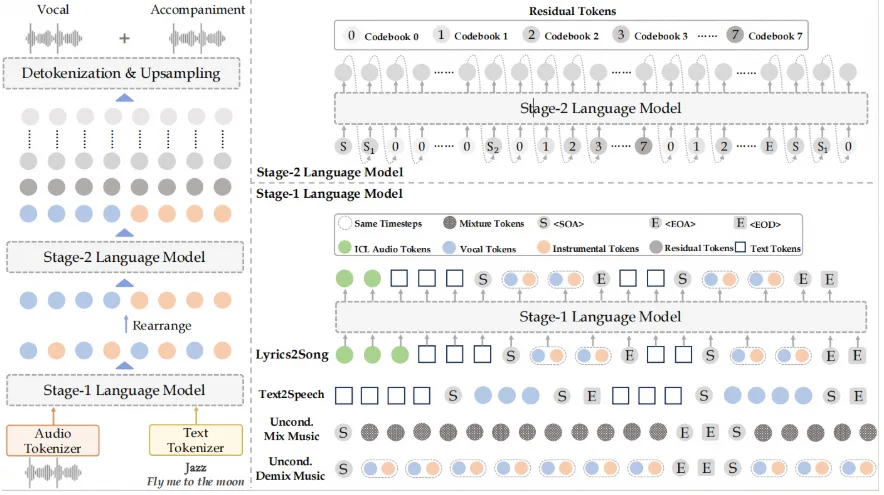
Підсумкова модель може генерувати композиції різними мовами та працює в багатомовному режимі. Наприклад, рядки пісні можуть бути одразу трьома мовами. У такому разі нейромережа згенерує коректну композицію.
Зазначається, що для запуску YuE необхідно досить багато вільної відеопам’яті. Наприклад, для запуску двох сесій (генерація одного куплету й одного приспіву) потрібно близько 24 ГБ пам’яті. Для запуску чотирьох і більше сесій вже буде потрібно не менше 80 ГБ відеопам’яті. Також наголошується, що генерація 30 секунд аудіо на Nvidia H800 займе 150 секунд, а на декількох RTX 4090 – 360 секунд.
Код проєкту опублікували на GitHub. Крім коду в репозиторії є інструкції із запуску та поради щодо складання запитів. Приклади роботи нейромережі доступні на офіційному сайті. Текст дослідження автори проєкту опублікують пізніше.


