Дослідники Google розробили новий тип моделі Transformer, яка дає мовним моделям щось схоже на довготривалу пам’ять. Система може обробляти набагато довші послідовності інформації, ніж поточні моделі, що призводить до кращої продуктивності при виконанні різних завдань.
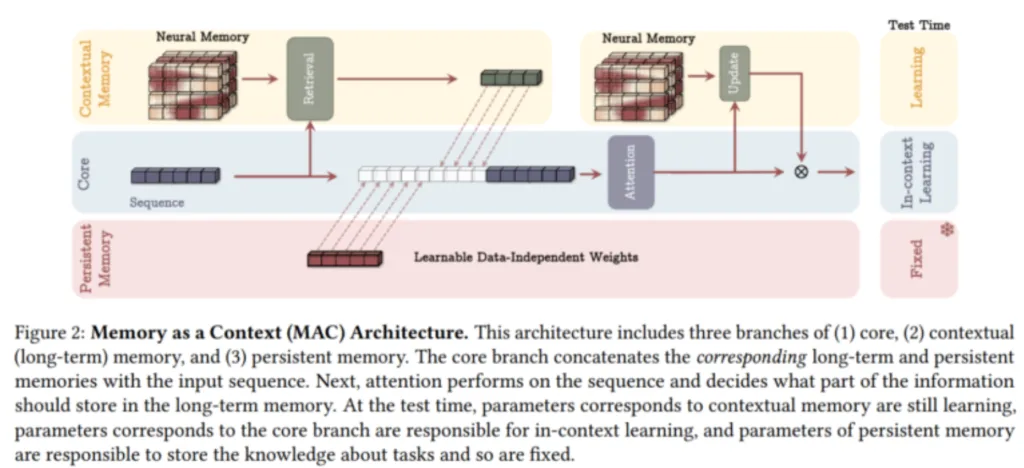
Нова архітектура «Titans» черпає натхнення з того, як працює людська пам’ять. Об’єднуючи штучну короткострокову і довгострокову пам’ять через блоки уваги та MLP пам’яті, система може працювати з довгими послідовностями інформації.

Однією з розумних функцій системи є те, як вона вирішує, що запам’ятовувати. Titans використовує «здивованість» як свою основну метрику – що несподіваніша інформація, то більша ймовірність, що вона збережеться в довготривалій пам’яті. Система також знає, коли слід забувати речі, що допомагає їй ефективно використовувати простір пам’яті.
Команда створила три різні версії Titans, кожна з яких по-різному обробляє довготривалу пам’ять: пам’ять як контекст (MAC), пам’ять як контроль доступу (ворота) (MAG), пам’ять як шар (MAL). Хоча кожна версія має свої сильні сторони, варіант MAC особливо добре працює з дуже довгими послідовностями.
Під час великого тестування Titans перевершили традиційні моделі, як-от класичний Transformer, і новіші гібридні моделі, як-от Mamba2, особливо під час роботи з дуже довгими текстами. Команда стверджує, що він може ефективніше обробляти контекстні вікна понад 2 мільйони токенів, встановлюючи нові рекорди як для моделювання мови, так і для прогнозування часових рядів з довгими контекстами.
Система також досягла успіху в тесті «Голка в копиці сіна», де їй потрібно знайти певну інформацію в дуже довгих текстах. Titans досягла точності понад 95% навіть із текстами з 16 000 токенів. Хоча деякі моделі від OpenAI, Anthropic і Google працюють краще, вони набагато більші – найбільша версія Titans має всього 760 мільйонів параметрів.
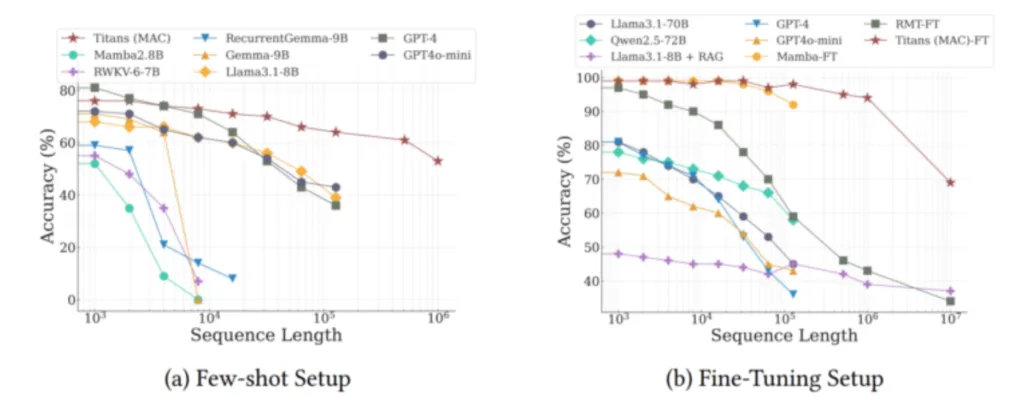
Titans дійсно показала свою силу в тесті BABILong, складному тесті на довгострокове розуміння, де моделі повинні пов’язувати факти, розкидані по дуже довгих документах. Система перевершила більші моделі, такі як GPT-4, RecurrentGemma-9B і Llama3.1-70B. Вона навіть перевершила Llama3 з Retrieval Augmented Generation (RAG), хоча деякі спеціалізовані моделі пошуку все ще працюють краще.
Команда розраховує зробити код загальнодоступним у найближчому майбутньому. Хоча Titans і подібні архітектури можуть призвести до мовних моделей, які обробляють довші контексти та роблять кращі висновки, переваги можуть вийти за рамки простого опрацювання тексту. Ранні тести команди з моделюванням ДНК показують, що технологія може поліпшити й інші додатки, включно з відео-моделями, за умови, що багатообіцяючі результати тестів підтвердяться в реальному використанні.


