Mistral щойно випустили багатомовний, мультимодальний 24B LLM із продуктивністю SOTA з контекстом 128K і ліцензією Apache 2.0
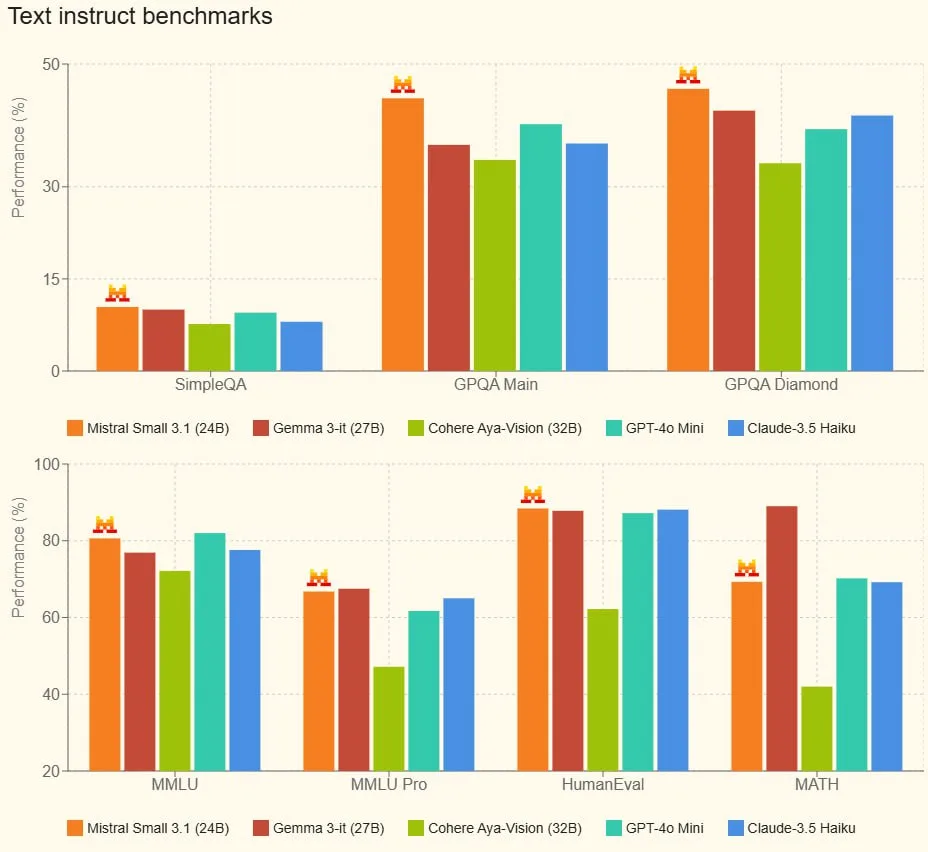
Модель перевершує аналогічні моделі, як-от Gemma 3 і GPT-4o Mini, забезпечуючи при цьому швидкість інференсу 150 токенів на секунду.
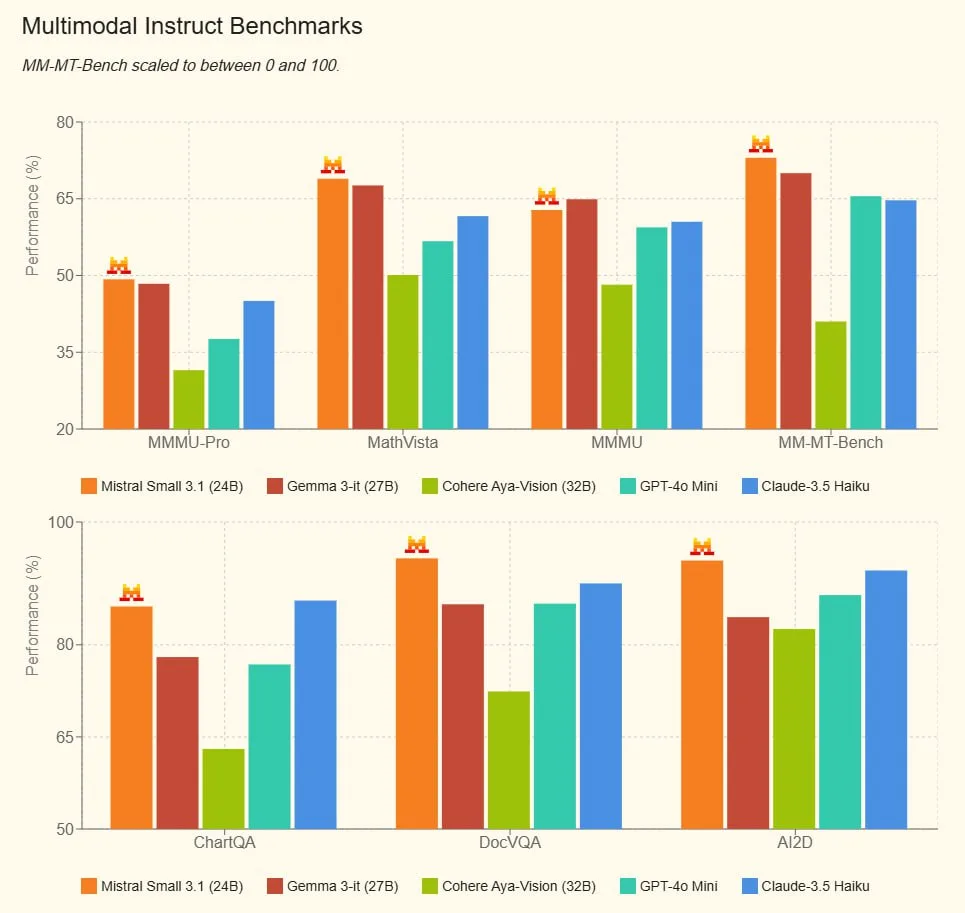
Це нова версія компактної мовної моделі від Mistral.ai, розроблена для забезпечення високої продуктивності при мінімальних обчислювальних витратах.
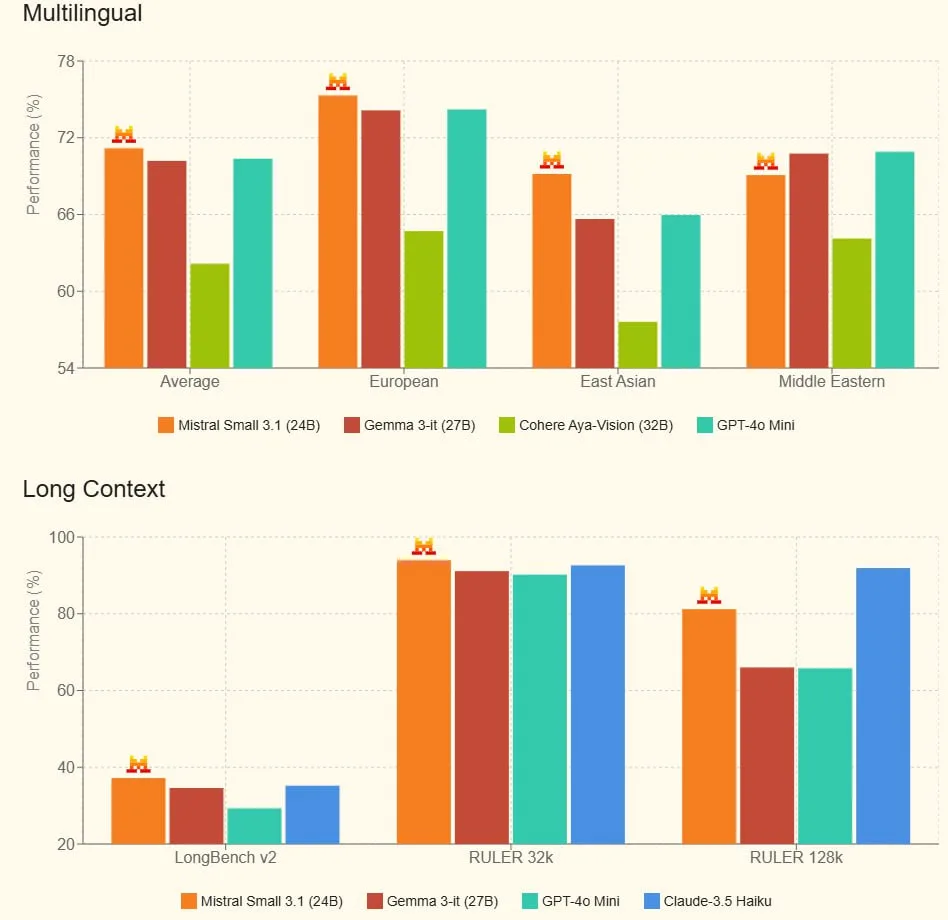
- Оптимізована архітектура: Поліпшення в конструкції моделі дають змогу знизити затримки інференсу та підвищити точність генерації, що особливо важливо для додатків у реальному часі. Mistral Small 3.1 може працювати на одному RTX 4090 або Mac з 32 ГБ оперативної пам’яті.
- Ефективне використання ресурсів: Завдяки зниженим обчислювальним вимогам, модель ідеально підходить для роботи на пристроях з обмеженими ресурсами – від мобільних телефонів до хмарних серверів.
- Широкий спектр застосування: Mistral Small 3.1 зберігає баланс між компактністю та якістю, що робить її універсальним інструментом для задач обробки природної мови: від чат-ботів і віртуальних помічників до систем аналізу текстів.
- Стабільність і надійність: Нова версія демонструє поліпшену стійкість і передбачуваність роботи, що допомагає розробникам створювати якісніші та надійніші додатки.


